

We’ve spent the last decade solving the visibility problem.
Most modern systems are deeply instrumented. Request rates, error counts, tail latency, deploy markers, dependency health, infrastructure saturation — it’s all there. In many environments, the question isn’t whether you have signals. It’s whether you have too many of them.
This explosion of observability in SRE environments has created a new illusion: if you can see everything, you must understand everything.
You don’t.
Understanding still requires work. Hard, expensive, human work. And it shows up in one place: investigation time.
And when investigation time grows, so does SRE cost.
The Real Cost of Incident Management Isn’t Alerts — It’s Investigations
Here’s the uncomfortable math. An alert is just a signal crossing a threshold — it costs nothing. What costs you is what happens next.
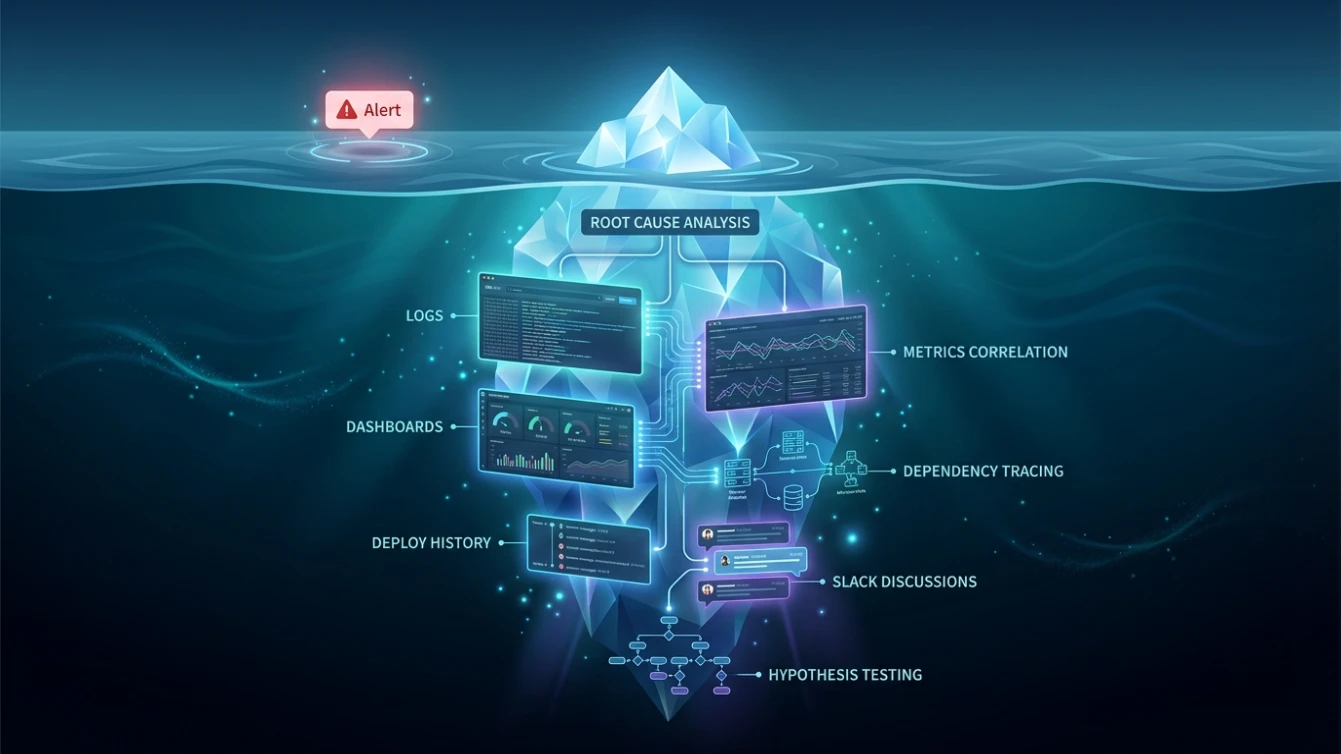
Someone has to stop what they’re doing and reconstruct what happened. They check recent deploys. They chase correlated anomalies across a half-dozen dashboards powered by SRE observability tools. They pull logs. They ping someone on another team to ask if anything changed. They form a hypothesis. Test it. Discard it. Start over.
This is the daily reality of incident response management.
And it’s not abstract toil. It’s toil SRE teams experience every week. Your most experienced site reliability engineers spend hours — sometimes entire shifts — answering one question: what just happened?
You know how often this plays out. You know roughly how long root cause analysis (RCA) takes. You know what those engineers could be building, improving, or preventing if they weren’t buried in incident reconstruction.
The math doesn’t have to be precise to point in a direction.
Why Site Reliability Engineering Gets Harder as Organizations Scale
Here’s what’s easy to miss: investigation volume doesn’t just grow with traffic. It grows with interaction.
Every new service multiplies dependencies. Every dependency multiplies failure modes. Every new deploy cadence expands the change surface. Ownership fragments across SRE, platform engineering, DevOps, and development teams. Tribal knowledge spreads thin — and often evaporates entirely when someone leaves.
None of this is anyone’s fault. It’s what scaling software organizations naturally produce.
But the downstream consequence is that reconstructing system state gets harder over time, not easier. Your engineers might get sharper, but the system they’re reasoning about keeps outpacing them. That’s where the pressure comes from — not incompetence, not laziness. Complexity.
The Hidden Cost of SRE Toil on Engineering Velocity
When senior SREs spend the majority of their week rebuilding timelines and correlating signals across your observability and log management stack, that time doesn’t go toward hardening architecture or eliminating classes of failure. It goes toward answering what already broke. This is the structural problem of toil reduction in SRE.
You can run an organization this way for a while. A lot of teams do.
But there’s a tipping point. When the ratio of reactive incident management to preventative reliability work keeps tilting in the wrong direction, roadmaps slip. SLAs get harder to protect. Reliability plateaus. And the only lever that seems available is hiring — which scales SRE cost almost perfectly with investigation volume while doing nothing to change the underlying dynamics.
More people chasing more alerts isn’t a strategy. It’s deferred debt.
What Most AIOps and AI SRE Tools Get Wrong
This is where the conversation about AI for site reliability engineering gets serious — not because it’s a trend worth chasing, but because it targets the right variable.
If the dominant cost driver is human investigation time, then the only durable way to bend the curve is to reduce the human time required per investigation. That’s the lever behind AI SRE ROI.
The problem is that most platforms marketed as AI SRE or AIOps don’t actually pull it.
Faster summaries, richer dashboards, more comprehensive alert correlation — if the engineer still has to retrace every step, validate every conclusion, and independently rebuild the reasoning, the work hasn’t been removed. It’s been re-wrapped. And when the output is wrong often enough, you don’t save time. You spend extra time investigating the AI in addition to the incident. That’s not leverage. That’s overhead.
Real AI SRE ROI comes down to three things most vendors would rather you not examine too closely:
- Whether the reasoning is actually accurate
- Whether the system learns and compounds over time
Whether it’s shifting your team from reactive firefighting to proactive reliability engineering
Why AI SRE Needs to Learn Like a Human Teammate, Not a Search Index
The second failure mode of most AI operations tools is subtler: they’re static.
They ingest historical logs and metrics from observability in SRE environments, apply pre-trained models, and surface patterns from the past. Useful, sure. But imagine hiring a new engineer who only ever looks in the rearview mirror — one who can tell you everything about every incident that already happened, but has no ability to learn from working alongside your team, absorb your tribal knowledge, or reason about what’s coming. You wouldn’t call that a teammate. You’d call it a search index with a Slack handle.
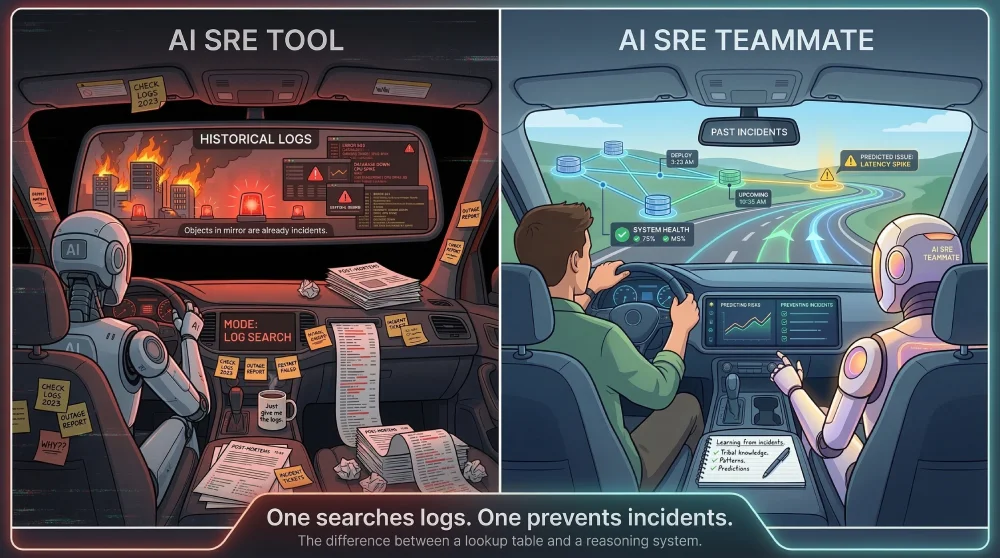
That’s what most AI SRE tools actually are. And navigating by rearview mirror is fine until the road curves.
A genuine AI agent SRE teammate operates differently — one who learns from every incident it runs, remembers that the last three times a specific service degraded in this pattern the root cause was a misconfigured rate limiter in the upstream dependency, and absorbed the post-mortem, the Slack thread where someone noticed the leading indicator, and the institutional knowledge that never made it into a runbook.
That means learning from outcomes — both successful resolutions and false positives — and updating its reasoning accordingly. It means ingesting tribal knowledge across the organization. And it means reasoning forward, not just backward: using current system behavior and recent change velocity to surface emerging reliability risks before they become incidents.
The difference between a lookup table and a reasoning system is compounding returns. One applies the same pattern library indefinitely. The other gets meaningfully better every time it works alongside your team.
From Reactive Incident Response to Proactive Reliability Engineering
Faster firefighting is better than slower firefighting. But the real opportunity isn’t in MTTR — it’s in reducing how many fires start.
An AI SRE agent operating at the level of a senior reliability engineer isn’t just compressing mean time to resolution. It’s continuously analyzing the system for reliability debt: services operating closer to failure thresholds than anyone realizes, architectural patterns that have historically preceded production incidents, configuration drift accumulating quietly across environments.
This is where SRE toil reduction becomes structural rather than incremental. Toil — the repetitive, manual work of incident response, escalation coordination, and log management triage — doesn’t decrease when you add headcount. It scales with it. An AI SRE teammate that proactively surfaces reliability risks before they surface as alerts changes the equation entirely.
The framing shift matters: investigation costs are a tax on the present. Reliability investment is a multiplier on the future. When senior engineers stop spending most of their week reconstructing what just broke and start spending it eliminating what will break, you’re not just improving MTTR. You’re changing the trajectory of incident frequency.
How to Measure the ROI of an AI SRE Teammate
Most teams evaluating AI for site reliability engineering end up measuring the wrong things: response latency, alert coverage, how comprehensive the summaries look.
The only metric that matters is simple: how much real human investigation time disappeared?
Not how fast it generated an answer. Not how many alerts it touched. Not whether the dashboard looks more impressive than what you had before.
How much time did your engineers not spend on root cause analysis, incident reconstruction, and log management triage — and what did they do with it instead? Did incident frequency decline over the following quarters? Did mean time to detection improve because the AI SRE agent was flagging issues before they became alerts?
If those numbers move meaningfully, you’ve changed the economics of reliability. If they don’t, you’ve added complexity to an already complex system.
The Structural Problem AI-Assisted Coding Is About to Make Worse
Alert growth isn’t going to slow down. If anything, the acceleration of software development — particularly with AI-assisted coding increasing deploy velocity and expanding system surface area — means the complexity your SRE team is reasoning against will keep compounding.
More signals. More dependencies. More novel failure modes at the intersections of services no one designed to interact.
If the unit cost of investigation stays constant while volume grows, total cost grows. That’s just arithmetic. The only way out is to reduce the cost per investigation while simultaneously driving down the investigations that need to happen at all.
More dashboards don’t do that. More process doesn’t do that. More headcount doesn’t do that.
An AI SRE teammate that earns trust by compounding learning over time, and actively shifts your team from reactive incident management to proactive reliability engineering — that changes the structure of the problem.
The uncomfortable question for reliability leaders isn’t whether AI SRE is interesting.
It’s whether your current investigation model scales with the complexity you’re actively building.
If it doesn’t, what you’re feeling isn’t a rough quarter.
It’s structural.
AI SRE ROI FAQs
1. What is AI SRE and how does it differ from traditional AIOps?
AI SRE applies advanced AI reasoning and automation to site reliability engineering workflows, particularly incident investigation and reliability analysis. Unlike traditional AIOps platforms that focus primarily on alert correlation and dashboards, AI SRE systems aim to automate investigation and root cause reasoning across services, infrastructure, and deployments.
2. Why do many AI SRE tools fail to deliver real ROI?
Many AI SRE platforms promise faster incident response but fail to meaningfully reduce investigation time. If engineers still need to manually validate AI outputs, the tool adds overhead rather than removing work.
True AI SRE ROI comes from reducing the amount of human investigation required during incidents and enabling teams to focus on proactive reliability improvements instead of reactive troubleshooting.
3. How can AI reduce SRE toil?
A large portion of SRE work involves repetitive investigation tasks such as correlating metrics, logs, deployments, and service dependencies. These manual processes create operational friction known as toil in SRE.
AI systems designed for reliability engineering can automate parts of this investigative workflow, enabling toil reduction in SRE by generating timelines, correlating signals across systems, and identifying probable root causes faster than manual analysis.
4. Do SRE observability tools already solve the investigation problem?
Modern SRE observability tools provide extensive visibility into system performance, but visibility alone does not equal understanding. Metrics, traces, and logs still require engineers to manually connect signals and reconstruct what happened during an incident.
AI SRE approaches aim to build on top of observability by reasoning across these signals automatically, helping teams move from simply seeing problems to actually understanding them faster.
5. What does it mean for AI to act as an AI SRE teammate?
An AI SRE teammate is designed to work alongside site reliability engineers rather than replace them. By analyzing telemetry, correlating alerts, and accelerating root cause analysis, an AI SRE tool can investigate incidents across complex systems and surface insights faster than manual workflows. When used this way, an AI SRE platform helps teams reduce cognitive load, enable SRE toil reduction, and strengthen reliability in AI SRE while keeping human expertise at the center of operational decision-making.
6. How does AI SRE impact SRE cost over time?
The largest contributor to SRE cost is not tooling or infrastructure, it’s engineering time spent on investigation and incident response.
By reducing investigation time and enabling proactive reliability improvements, AI SRE can shift engineering effort away from reactive firefighting and toward preventing incidents altogether. Over time, this change can significantly improve AI SRE ROI by lowering operational overhead and improving system reliability.