
AI for SREs: The Power of Cross-Domain Correlation in Root Cause Analysis
Ananda Rajagopal
Read time:
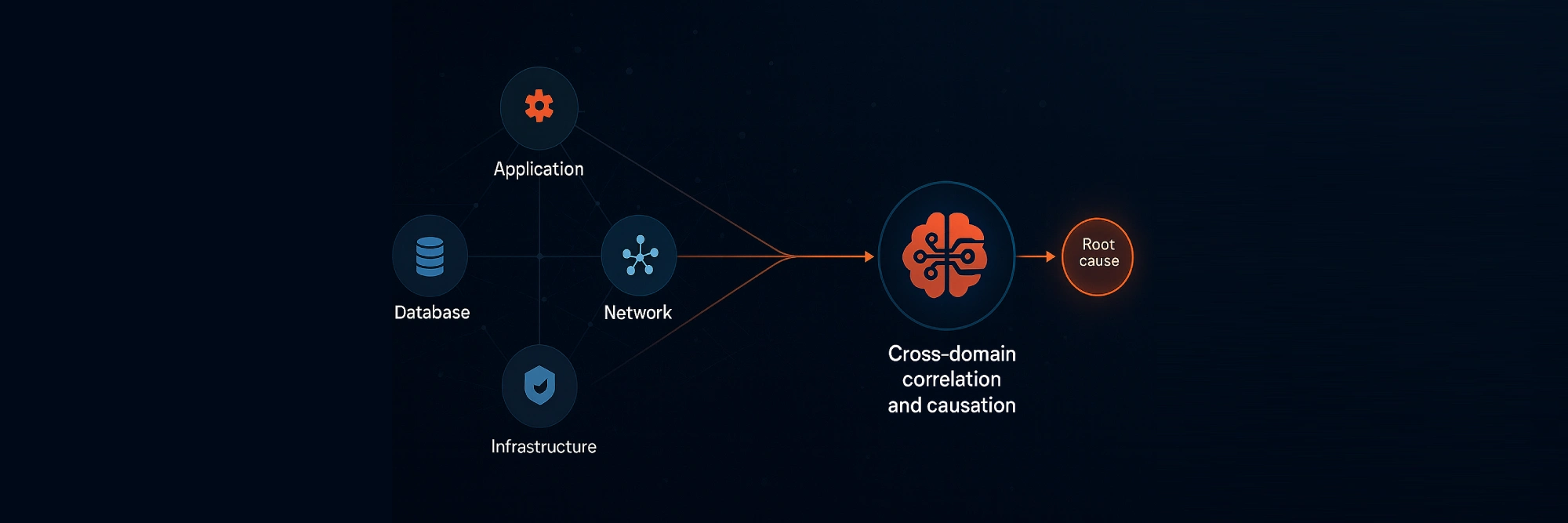
Discover how AI-driven cross-domain correlation transforms incident investigation and slash MTTR for modern SRE teams
Introduction
How valuable is AI for SREs? This question has sparked spirited debate across forums like Reddit and at major industry and reliability conferences. To cut through the noise, we’re launching a new series — “AI SRE Teammate Chronicles” — featuring real-world insights and customer learnings from deployments of the Ciroos AI SRE Teammate.
This series explores how AI-powered correlation, reasoning, and automation can drastically shorten mean time to resolution (MTTR) and eliminate toil in complex distributed systems. For the first article, we focus on a foundational concept that underpins most reasonably complex incidents in production: cross-domain correlation.
The Paradox of Domains
To begin with, it is important to examine a structural paradox at the heart of most organizations– the paradox of domains.
A domain is a logical area of functional responsibility where components or members share similar characteristics or purpose. Domains may be technical – such as applications, database, infrastructure, network, or security – or business-oriented, such as retail banking in a financial institution, inventory management in retail, or flight operations in an airline. Members of a domain naturally develop deep subject matter expertise within its boundaries.
Domain boundaries shape both software architectures and organization structures. They encourage modular design, clear ownership, and faster execution. They work well – until it doesn’t. When failures occur, the same boundaries that once fostered agility can create friction. Because organizations reward ownership, most engineers often start with quickly establishing “proof of innocence” within their domain rather than searching across boundaries for the shared root cause.
As enterprise architectures grow in complexity, this creates a paradox: the very modularity that enables scale and agility can hinder collaboration when issues span multiple domains. Remediating these incidents typically requires system thinkers – senior architects or SRE leaders who see the forest beyond the trees. These systems thinkers are among the most valuable resources in that organization. To protect their time and streamline troubleshooting, organizations add escalation layers, ticket queues, and handoffs — often at the cost of agility. The result is longer resolution times and slower feedback loops.
Can AI help reimagine this paradox– preserving the benefits of domain ownership while minimizing the delays of cross-domain investigation?
Understanding Cross-Domain Correlation and Causation
At Ciroos, we founded the company on a core insight shaped by decades of experience building and operating large-scale distributed systems and observability platforms:
The hardest part of incident management isn’t just the volume of data—it’s the number of domains involved, and the reality that very few engineers in an organization possess deep expertise across them all.
When incidents span multiple domains, diagnosing the contributing factors, i.e. the true root cause(s) becomes exponentially harder. That’s why, even in highly automated environments, critical incidents still trigger crowded “war rooms.”
AI changes that. AI is exceptionally good in large-scale analysis. By analyzing signals objectively across all domains, AI can shift the focus from “not my domain” to “what’s the true root cause(s)”?
To achieve this, effective AI-driven incident analysis must understand correlation and causation across domains—what we at Ciroos call cross-domain correlation. This approach analyzes how seemingly independent events interconnect, revealing the true underlying failure chain.
Cross-Domain Correlation with the Ciroos AI SRE Teammate
At Ciroos, we’ve developed a set of patent-pending AI technologies called behavior patterns that power our analysis engine. Ciroos maintains a real-time knowledge graph that models dependencies across services, infrastructure, and configurations unique to each customer environment.
Ciroos generates a dynamic investigation plan and begins investigation using a candidate behavior pattern to diagnose the source alert. Ciroos enriches the alert with contextual metadata from the knowledge graph. This is akin to a human expert gathering the necessary data and picking a starting point for their analysis. An orchestrator selects a specialized AI agent to execute that behavior pattern. Unlike a static runbook with predefined steps, a dynamic investigation plan evolves based on observations collected at each stage, allowing the system to determine subsequent actions adaptively.
A Real-world Example
Here’s a real-world example from one of our own pre-production environments — a demonstration of how the Ciroos AI SRE Teammate rapidly performed a root cause analysis across multiple domains. (Yes, we use our own product in our operations — we drink our own champagne!)
Note: Although the system performs numerous “AI turns”, only the key ones are shown below for brevity. An AI turn is one complete sequence of reasoning, execution, and observation of the resulting data.
Processing the Source Alert and Generating a Dynamic Investigation Plan
In this deployment, Ciroos received an alert from an observability platform (Splunk) indicating that a front-end service pod was deleted. A recent deployment with a scheduled upgrade had been rolled out earlier. Was that a plausible cause?
The AI SRE Teammate initiated its reasoning process by selecting a candidate behavior pattern and leveraged the knowledge graph to identify upstream and downstream dependencies. Because the event originated from a service pod deletion, the system selected the behavior pattern that evaluates potential pod evictions due to resource pressure or node conditions. The Kubernetes agent (k8sagent) was chosen to execute this analysis.
Identifying the Failure Domain
The k8sagent examined the cluster and observed that the original frontend pod referenced in the source alert no longer existed, while its replacement pod was stuck in ImagePullBackOff state. The agent confirms that both pods were scheduled on the same node.
The orchestrator instructed the k8sagent to collect detailed logs and replica set information, and confirmed that Kubernetes itself was healthy. There were no resource pressure or eviction events. Node resource utilization was normal. The replica set was available, but below the desired replicas. There were no cluster-wide warning events indicating instability. At this point, the system concluded that the frontend pod service disruption issue was not within the Kubernetes domain.
Understanding the Lifecycle of Changes
Next, the orchestrator invoked another AI agent, the auditagent, to reconstruct the lifecycle of the original pod. The auditagent confirmed that the pod life cycle was normal– it was scheduled, pulled the image, created the container, and started successfully. A "Killing" event occurred approximately five minutes before the alert – consistent with a deployment update. No eviction or error events were recorded, and the container image had previously been pulled successfully.
Invoking a New Domain Agent
Armed with the prior findings including the knowledge that the replacement pod is in ImagePullBackOff state, the orchestrator now invoked a new domain agent to check the underlying infrastructure. This specific cluster was deployed in AWS. Therefore, the orchestrator instructed the awsagent to perform a series of checks on the underlying AWS configurations, including a properly attached internet gateway, NAT gateway, DNS, underlying EC2 instance details (for worker nodes), route tables, security groups, network access control lists (ACL) etc.
During these checks, the awsagent discovered that a network ACL had overly restrictive egress rules, allowing outbound traffic only to allowlisted IPs and internal networks (10.0.0.0/8). A default “deny all” rule (0.0.0.0/0 DENY) blocked all other traffic — including access to the container registry. This configuration prevented the new pod from pulling its image, explaining the ImagePullBackOff state.
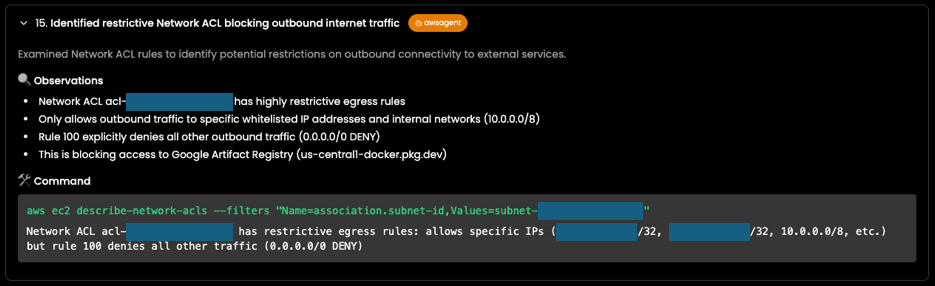
As a final step, the orchestrator asked the awsagent to verify the Elastic IP configuration to ensure that the NAT Gateway has the correct public IP assignment for outbound connectivity. After all, there could be multiple contributing factors that may have led to the issue. With all findings aligned, the Ciroos AI SRE Teammate identified the root cause: a restrictive NACL rule introduced a cross-domain dependency failure between the Kubernetes and network domains.
Assembling the Full RCA
The Ciroos AI SRE Teammate automatically compiled a complete evidence chain (see figure below) — together with the timeline of events, correlated alerts, affected components, recommendations, similar investigations, change requests, and a visual topology view — into a structured Root Cause Analysis (RCA) report for post-incident review. Optionally, the RCA report can also be edited for additional annotations.
This entire investigation, including the recommendation with updated configurations to fix the deployment, was completed in just minutes by Ciroos.
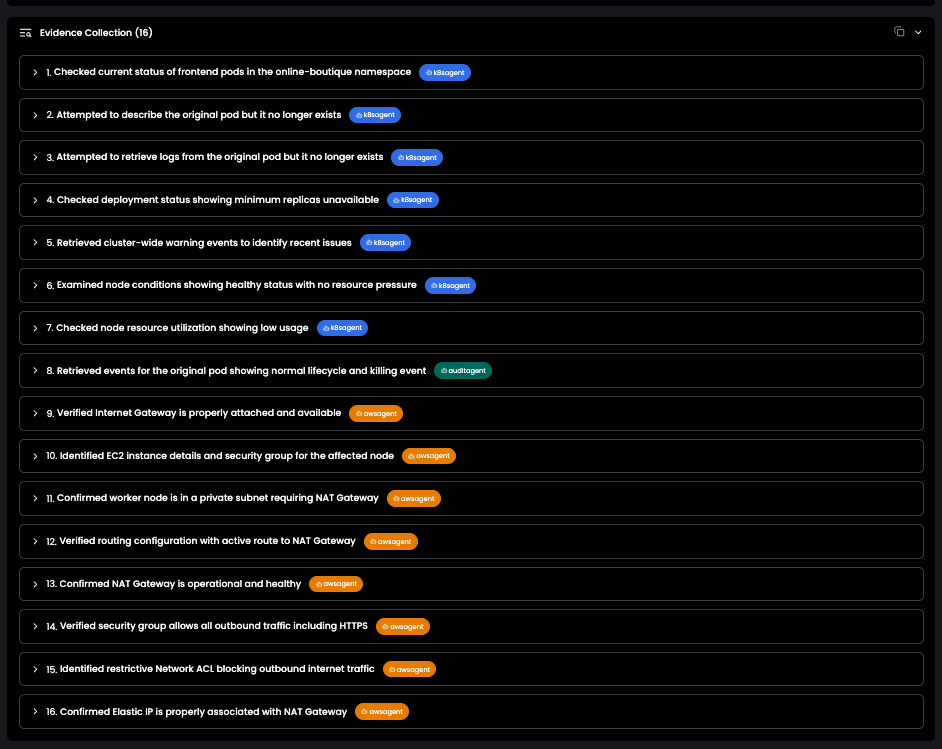
Post-incident review
Post-incident review revealed that the security network ACL change had been made by a security engineer with good intentions — to tighten up security controls as part of a zero-trust security initiative. Because this change had happened several days prior to the frontend change, it wasn’t immediately obvious to the engineer debugging the issue as to what had caused the issue … until the Ciroos AI SRE Teammate diagnosed it correctly.
Conclusion
Understanding causal relationships across domains is essential for accurate and rapid root cause analysis. Much like the Five Whys framework, Ciroos AI SRE Teammate uses an iterative, expert reasoning approach to identify the true source of failure rather than just its symptoms thereby preventing recurrence and improving reliability posture.
The Ciroos AI SRE Teammate is already helping enterprise teams:
- Cut mean time to root cause (MTTR) by over 95%
- Uncover hidden dependencies that traditional tools miss
- Reduce operational toil while keeping humans firmly in control
If your incidents still summon war rooms or drag on longer than they should, maybe it’s time to see how Ciroos AI SRE Teammate can change that!
👉 Learn more at www.ciroos.ai or contact us at https://ciroos.ai/request-a-demo to speak to one of our experts.
If this topic resonates with you, learn more at our webinar on Reliability in the Age of AI: What High-Impact SRE Teams Get Right —
February 25th 10AM PST / 1PM EST featuring:
- Niall Murphy (SRE Thought Leader & Author, ex-Google, Microsoft)
- Todd Underwood (SRE Thought Leader and Author, ex-Head of Reliability at Anthropic)
- Chirag Mehta (Vice President & Principal Analyst, Constellation Research)
- Ronak Desai (Co-Founder and CEO, Ciroos)
.png)





