The Fighter Pilot Framework That Explains Your Incident Queue
In military strategy, the OODA loop (Observe, Orient, Decide, Act) is a framework developed by US Air Force Colonel John Boyd. Drawing on his own combat experience, Boyd studied why certain pilots won aerial engagements and surmised that the pilot who could cycle through this loop faster and more accurately than the opponent would win. Speed and accuracy of decision, not just firepower, determined the outcome.
The framework maps directly to enterprise reliability. When an anomaly occurs, SREs must observe the signals, orient that data into context, formulate a decision hypothesis, and act on it. This mapping is directionally accurate, but in modern enterprise systems it is not perfectly operationally exact. Distributed ownership, siloed tooling, and asynchronous signals introduce friction at each stage of the loop.
For the past decade, as distributed systems have exploded in complexity, enterprise engineering and IT teams have recognized two challenges: there is friction at each stage of this loop, and verifying whether a remedial action worked is itself a manual process. The result is not only slower response, but inconsistent decision quality depending on operator experience, time pressure, and available context. As a result, the loop leaks time everywhere.
Where Bespoke Observability Fell Short
Make no mistake: observability tools are absolutely necessary. You cannot manage what you cannot see. Modern observability platforms provide critical capabilities—metrics, logs, traces, alerting, and correlation primitives—and are foundational to reliability engineering.
But the complexity of modern distributed systems has exposed a fundamental limitation: observability surfaces signals. It does not, by itself, produce decisions. In this context, reliability becomes a decision-making problem under uncertainty, not just a visibility problem.
The industry is wrestling with a data dilemma that practitioners rarely state plainly but universally understand. A consistent picture emerges: up to 90% of the telemetry data ingested by observability platforms is not needed for active incident resolution, excluding compliance requirements. The exact proportion varies widely by environment, workload, and maturity. However, the underlying issue is consistent: teams cannot determine in advance which data will be relevant during an incident. The critical caveat is that no one knows which 90% is unnecessary until an incident occurs.
Observability platforms were never designed for continuous, intelligent, 24×7 monitoring and action where feedback ties back into the system itself. They were designed to store data for retrospective investigation. While modern observability platforms have evolved beyond pure storage, the dominant operating model still relies heavily on human-driven investigation across disconnected signals.
Without an always-on intelligence layer watching your systems in real time, the only rational response is to retain everything, just in case. Some customers call it FOMO-based monitoring.
The AI SRE Layer: Reliability Through a Unified Feedback Loop
To fix the OODA loop, context gathering must be rethought at a foundational level. In modern environments, the challenge is not lack of data, rather, it is fragmentation of context across systems, teams, and time. This is precisely what the AI SRE layer is built for. More precisely, this layer aims to improve the orientation and decision phases by synthesizing disparate signals into actionable context.
Why a separate layer? Because the signals needed to understand a modern enterprise system are never contained within a single observability platform. True context is distributed across recent configuration changes, cloud infrastructure events, Slack threads from the last incident, ticketing systems, vendor dependencies, Confluence runbooks, and tribal knowledge held by individuals who may or may not be available when the next alert fires. In practice, incident resolution often requires stitching these sources together manually under time pressure.
A dedicated AI SRE layer acts as the connective tissue across these silos. It does not replace observability tools. It reasons across them, synthesizing a complete picture that no individual tool can produce on its own.
Why AIOps Fell Short
This must not be confused with the category historically called AIOps. That label has become a punchline in the industry, and for good reason. While some AIOps implementations delivered value, many struggled to meet expectations due to architectural limitations. Legacy AIOps relied on rules configured by humans, rigid machine learning models, and threshold-based clustering. These systems could not reason over unstructured context. They could not handle the variance of edge cases at enterprise scale. They could not adapt as systems evolved. Moreover, the ongoing operational burden was too high for the typical enterprise. As a result, adoption was uneven and often limited to narrow features such as alert correlation and deduplication.
What is Different Now
The new AI SRE layer is built on a fundamentally different architecture. Advances in AI enable more adaptive and context-aware systems. State-of-the-art AI SRE systems use a combination of deterministic logic and agentic reasoning to navigate unstructured context the way a team of expert human engineers would — across disparate data sources, without requiring every signal to be pre-formatted or pre-tagged. Such systems can correlate signals, generate hypotheses, and adapt over time by incorporating human context.
The below figure illustrates what a modern OODA loop looks like with an AI SRE layer in place. The system auto-observes from the right data sources, generates intelligent alerts with context to detect anomalies, and enriches that context with human knowledge to determine contributing factors. When guardrails permit, it acts through auto-remediation without waiting for a human to intervene. Critically, because the AI SRE system has visibility into live systems, it can close the loop by validating whether remediation worked and feeding that learning back into the next cycle. This is what a complete, self-improving OODA loop looks like in practice.
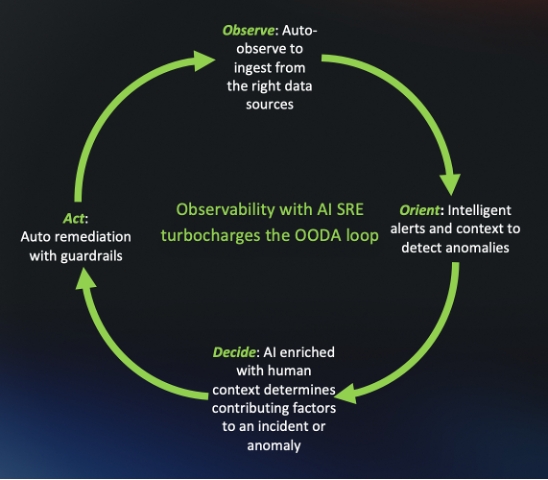
Figure 1: A modern OODA loop turbocharged by AI SRE
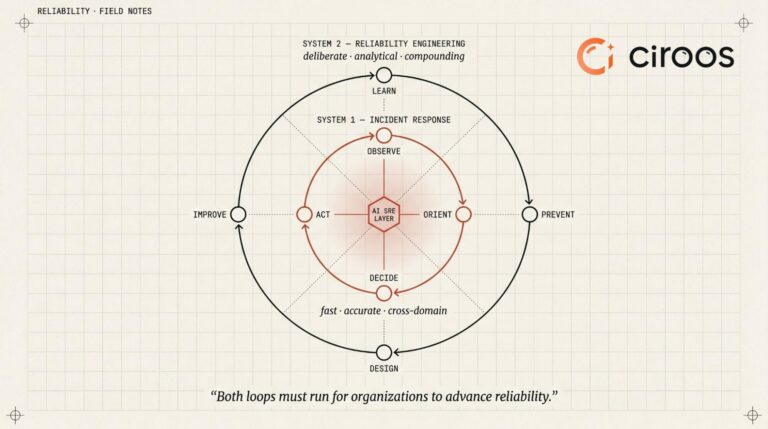
Two Loops, Two Kinds of Intelligence
Reliability is not achieved by hoarding data. MTTR numbers alone are not a sufficient indicator of a healthy system. Better reliability is achieved by accelerating the OODA loop: making faster, more accurate decisions with a complete picture of what is actually happening, bounded by the practical constraints of cost, security, and the pace of innovation.
Daniel Kahneman’s landmark work Thinking, Fast and Slow describes two modes of human cognition. System 1 is fast, instinctive, and pattern-driven. System 2 is deliberate, analytical, and provides compounding benefits. Kahneman’s central insight is that both are necessary — and that over-relying on one at the expense of the other is where decisions break down. Reliability engineering exhibits a similar structure: decisions made under pressure differ fundamentally from those made over time.
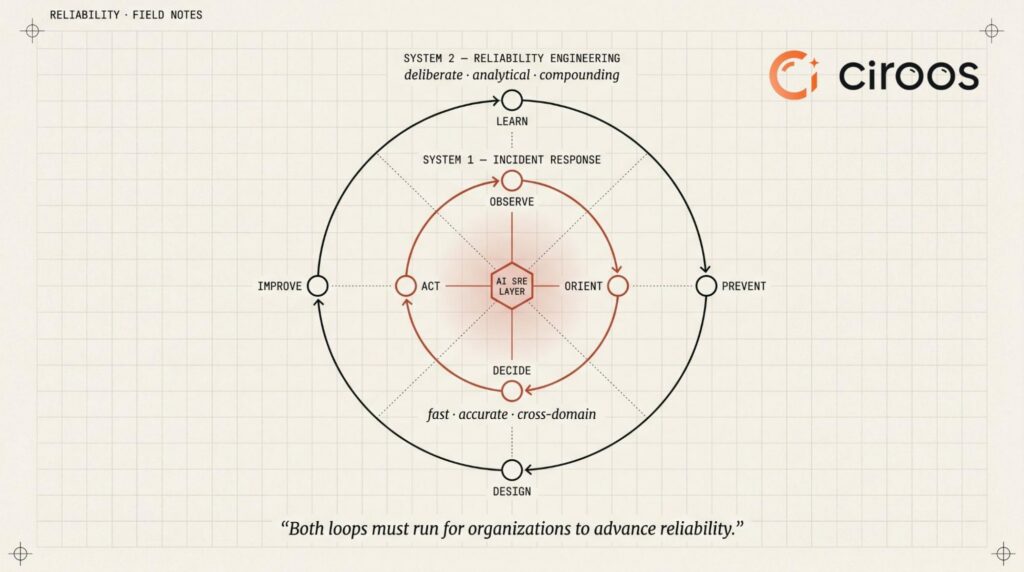
The inner loop is System 1. It operates at incident speed, pattern-matching against known signals, making fast decisions under pressure, and acting on remediation. Speed is the primary virtue. In a human SRE context, this is the on-call engineer who has seen this failure mode before and acts on instinct. The outer loop is System 2. It is deliberate and analytical. It asks the harder questions: what patterns are emerging across incidents, what systemic changes are needed, what can be prevented next time. It is not fast by design. It is thorough by design.
In many organizations, the inner loop is reactive and inconsistent, while the outer loop is underdeveloped or manual. The opportunity is not only to accelerate the inner loop, but to systematically strengthen the outer loop. For example, alert fatigue introduces availability bias—engineers prioritize what is visible, not necessarily what is causal.
In a typical enterprise, it is incredibly difficult to do this because of expertise gaps or time demands on the few systems thinkers in the organization. However, a well-designed AI SRE system working with human experts can address such questions continuously and at scale.
By implementing an intelligent layer that can orient complex, fragmented signals and act upon them, it becomes possible to materially reduce friction across every phase of the OODA loop simultaneously. The result is not just faster incident response—it is a fundamentally different relationship with operational reliability: one where the system learns continuously, where noise is reduced systematically, and where human experts spend their time on judgment rather than triage.
That is what it means to engineer reliability. Not to observe more. To understand better, and act decisively. Observability provides visibility. Reliable systems require continuous orientation, decision support, and feedback. The goal is not more data, but better decisions—made faster, with stronger evidence, and improved continuously over time. Improving the OODA loop should result in measurable gains across detection precision, time to validated hypothesis, repeat incident rate, and noise reduction.